Danna-Sep¶
Danna-Sep is a combination of three different sub-models: X-UMX, U-Net, and Demucs. Each sub-model has been modified either by training with a different objective, or by introducing some architecture changes. The final output is a linear combination of individual outputs from the sub-models.
Multi-Domain Inputs¶
The reason why we adopted a combinational approach is because it is known that source separation models which use spectrogram as inputs are effective on harmonic sources such as vocals, while those which use audio as inputs are effective on percussive sources such as drums. We aimed to combine the best of both worlds in our model. Below is the system diagram of our model.
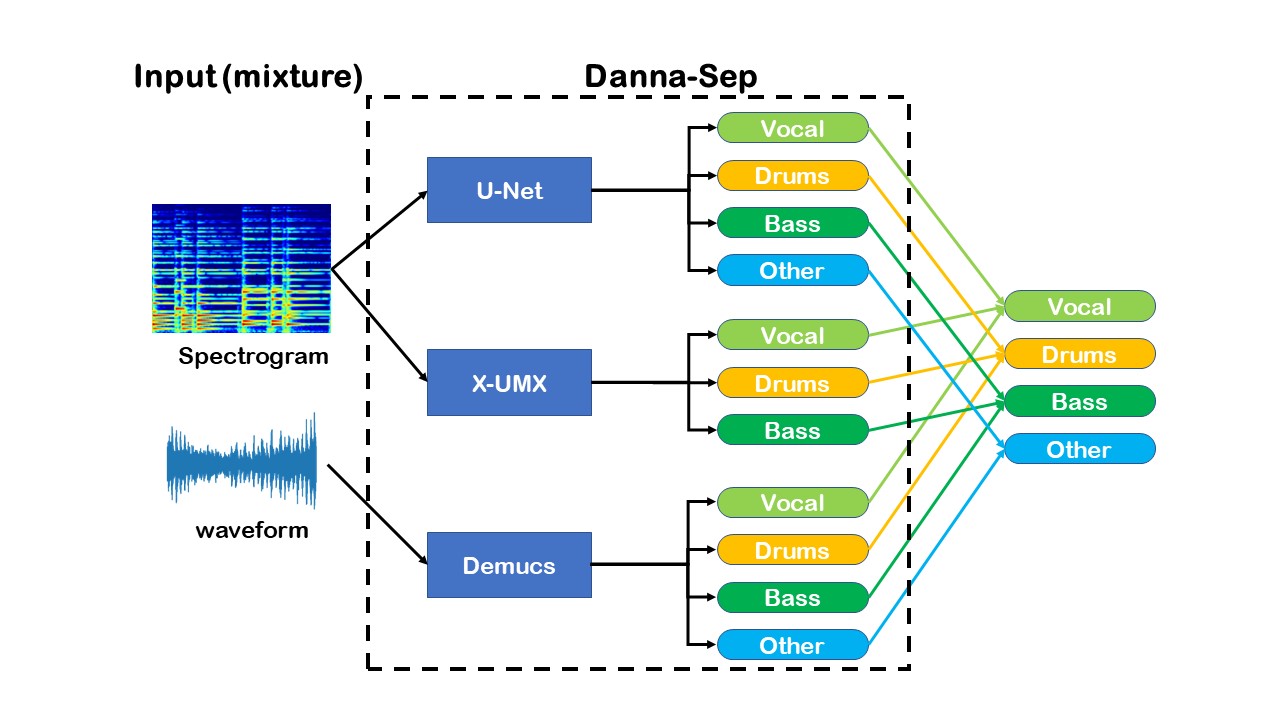
Fig. 4 The schematic diagram of Danna-Sep.¶
For more details about our model and the exact settings, please check our paper out Danna-Sep: Unit to Separate Them All presented at the MDX workshop in ISMIR 2021.
Experimental Results¶
We trained Danna-Sep on the training set of MUSDB18-HQ, and tested it on the test set of MUSDB18 using museval. The SDR results are presented below.
Drums |
Bass |
Other |
Vocals |
Avg. |
|
|---|---|---|---|---|---|
X-UMX (baseline) |
6.44 |
5.54 |
4.46 |
6.54 |
5.75 |
X-UMX (ours) |
6.71 |
5.79 |
4.63 |
6.93 |
6.02 |
U-Net (ours) |
6.43 |
5.35 |
4.67 |
7.05 |
5.87 |
Demucs (baseline) |
6.67 |
6.98 |
4.33 |
6.89 |
6.21 |
Demucs (ours) |
6.72 |
6.97 |
4.4 |
6.88 |
6.24 |
Danna-Sep |
7.2 |
7.05 |
5.2 |
7.63 |
6.77 |
It’s clear that our modifications to the baseline models indeed improve the performance, and by combining these sub-models, Danna-Sep surpasses all baselines by a large margin and achieves the state-of-the-art performance.
Resources¶
Inferences¶
We provide a pre-trained Danna-Sep as a python package and can be used as a command line tool, so users can separate their favorite songs using one simple command. The installation instructions are available here.
Training¶
If you want to replicate our experiments, or want to train Danna-Sep on your own datasets, please check out our repository. To use your own trained checkpoints, please install the inference tool first, then follow the instructions in the repository README.
Contact¶
Email: ya70201@gmail.com
Github/Twitter: @yoyololicon